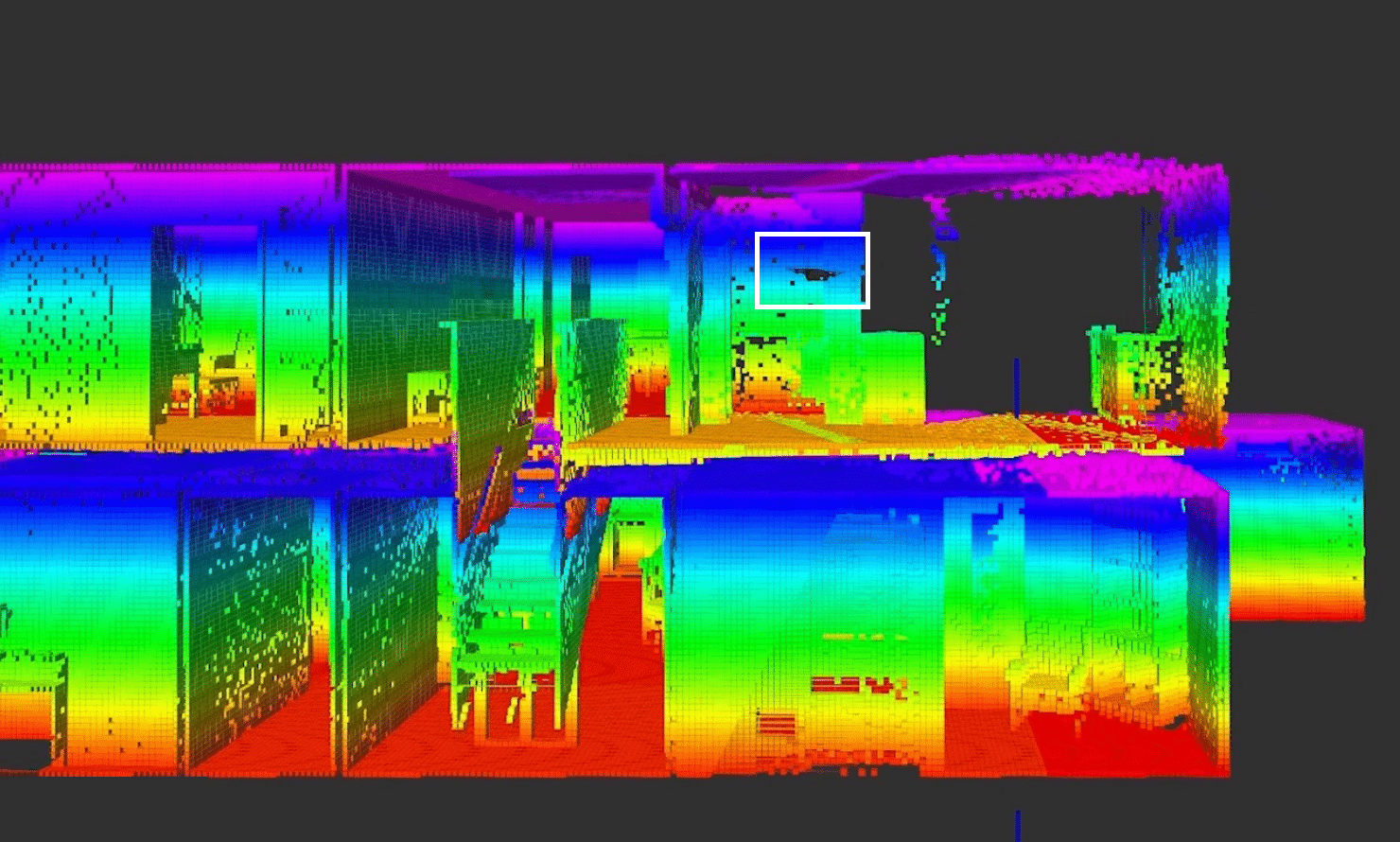
At Shield AI, our mission to develop intelligent, autonomous systems extends across diverse applications, from contested airspaces to intricate indoor
Read More

At Shield AI, we’re pushing the limits of human-machine collaboration, advancing Autonomous Collaborative Platforms (ACPs) to work seamlessly with piloted
Read More

Dear Team, As we close out 2024, I want to reflect on what has truly defined this year: the mission
Read More

This blog is part of a series of case studies highlighting the unique challenges and accomplishments of integrating Hivemind on
Read More
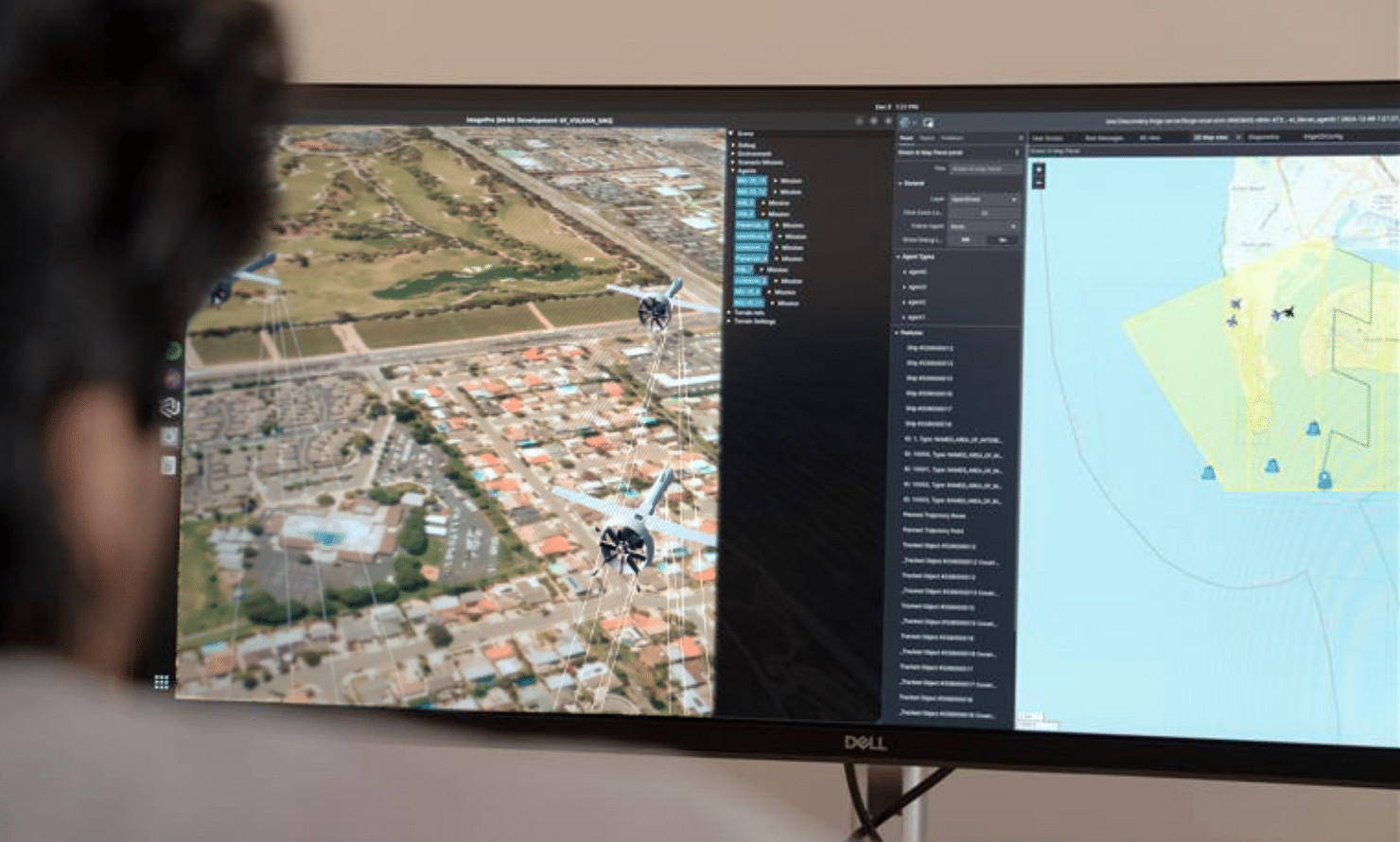
Developing autonomy software for defense and complex applications has traditionally been a monumental effort—one that demands not only time and
Read More
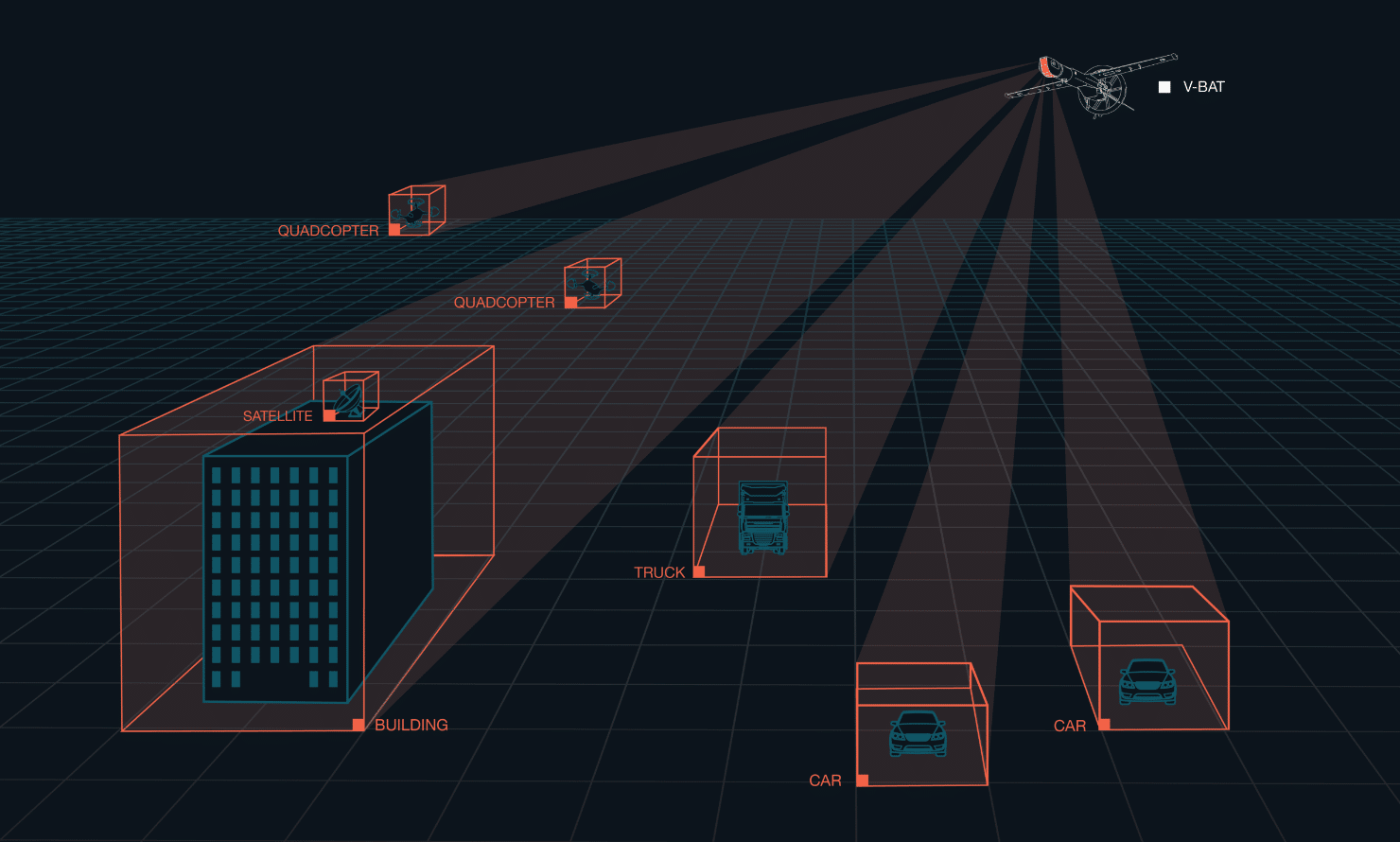
As defense and aerospace industries increasingly adopt autonomous systems, the demand for advanced, next-level autonomous solutions—such as adaptive, cognitive, and
Read More