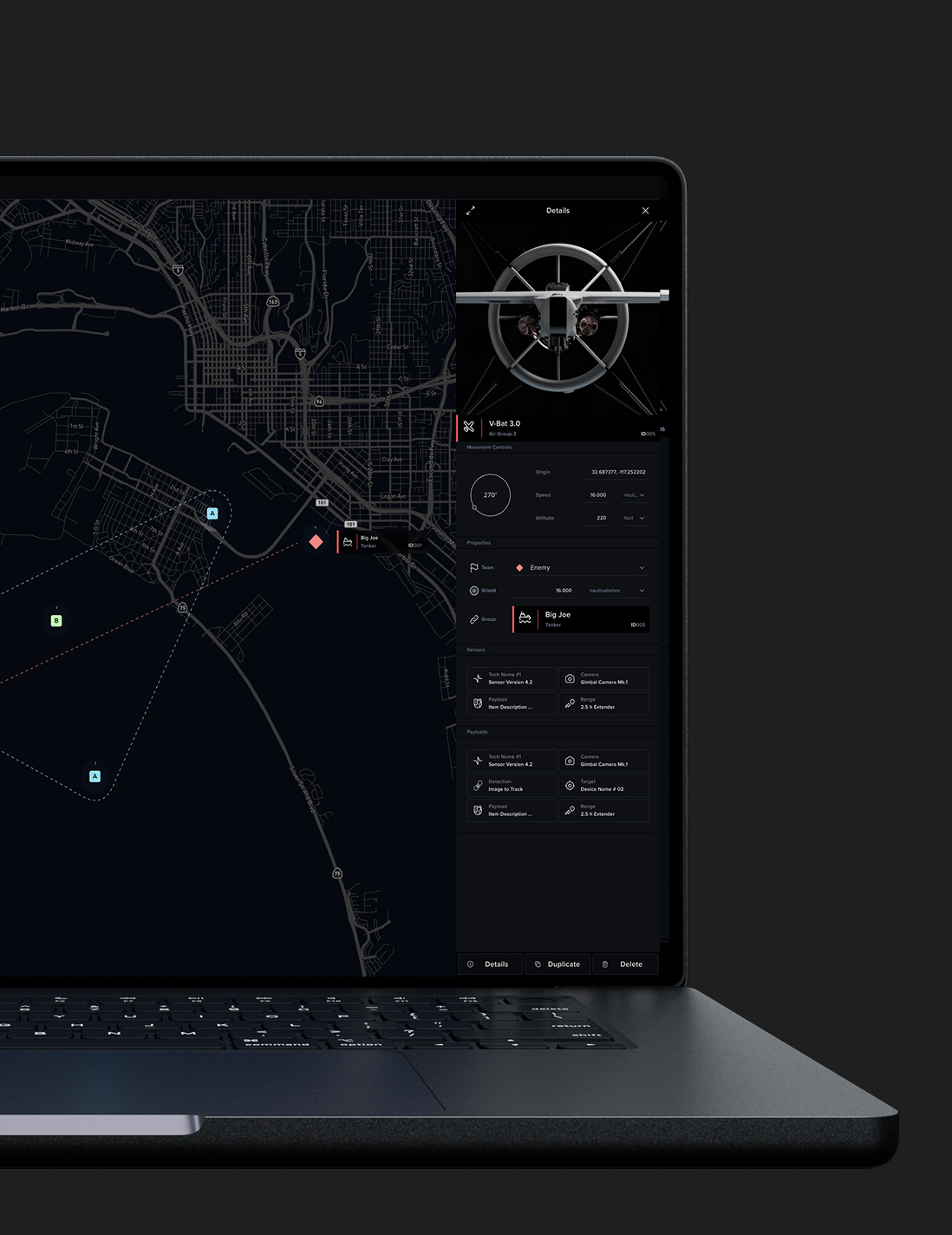





[July 17, 2019]
How Artificial Intelligence Manifests Through Exploration

A conversation with Professor Nathan Michael, Shield AI’s Chief Technology Officer. This is a continuation of our conversation about Trust and Robotic Systems.
In reference to robotic systems, what do we mean by exploration?
Typically, when we talk about exploration with an autonomous robotic system for the types of scenarios that we consider, we’re talking about deploying that robotic system into environments that are unknown. The goal of this deployment and exploration is to enable the individual robot to move through that environment, acquire information, and reduce uncertainty about the environment as it goes.
The challenge with exploration is that the system does not know what the environment looks like, so it needs to build up a map as it’s exploring the environment to reduce that uncertainty and effectively explore. By building up that map, the robot is figuring out how the environment is configured, where the environment expands and how to move through that environment to learn more about it.
How is exploration formulated? Said another way, how can we see intelligence manifest through exploration?
If we go back to the definition of exploration as a robot making decisions of where it should go in an environment in order to learn more and reduce uncertainty regarding that environment, then exploration is formulated as a question of figuring out what the current knowledge of the environment is and using that information to determine where the system should go to be able to learn more.
Consider a robot that is just starting to explore a new environment: At first it will only be able to see some small part of that environment. The area immediately around it will be perceived relatively clearly but the areas of the environment that are further away will be less clear. So, the robot is going to think about those areas of the map that it perceives clearly — that it understands — and it’s going to figure out which areas that it understands less or not at all. It’s going to decide to go to those places where it either has no understanding or minimal understanding, in order to better understand those areas. And it’s going to keep doing that until it is able to eliminate uncertainty and build a complete map of the environment.
As the robot explores, intelligence starts to manifest through its assessment of which observations of the environment are most informative. How this works is that at each instance in time, the robot is asking itself what action it should take in order to reduce its uncertainty with respect to the environment as observed presently. And that step enables it to assess and predict which one of these actions would be the most informative. It allows the system to think about how its ability to move is going to impact its understanding of the environment. So, intelligence starts to manifest as we build upon that step and start to move toward thinking about further steps out. Not just asking the question of what happens over the next few seconds, but asking what happens over the next many seconds. In order to do that, the robot will use prior insight and observations to predict what it’s going to see as it continues to explore.
This process of learning, or understanding how different actions translate into different information gain is directly related to these ideas of reinforcement learning, and this process of enabling the system to think about what actions it can take that most directly improve its exploration performance given a number of different factors such as the amount of time it takes or the amount of energy it expends. And the more the system does this, the more it learns about the environment, which in turn allows it to improve performance. This is achieved through extensive or continuous operation as a function of reinforcement learning.
How does this relate to reinforcement learning?
We’ve discussed reinforcement learning as this concept of learning based off some kind of reward. In this case, the reward can be thought of as the additional information gained through exploration.
So think of it this way: The robot can very easily think about what it sees presently of the world around it and it can very easily make really near term decisions of where it should go in order to learn more about that world. But the task of deciding where to explore next becomes a lot harder when the robot has to think about where it should go that’s further out.
And so what we do, when we explore an environment, is we leverage historical information about certain characteristics or traits of that environment, to inform the decisions that we make over longer horizons. Evaluating this information over longer horizons is important, because if we were to only make decisions based on the short term the system would perform suboptimally — we call this a “greedy optimization”.
Can you elaborate on this concept of a “greedy optimization”?
You can think of reinforcement learning as building up experience. The more a system explores a building, the better the understanding it builds of how to explore effectively. Then if it enters a similar environment, the system can use the same kinds of techniques employed previously to make it more effective. The more it explores, the better it’s able to think about not just what actions it should take instantaneously, but also what actions it should take over longer time horizons that will yield to superior performance.
Again, the reward here is the acquisition of information through that superior performance. The system is working to optimize its performance such that it is maximizing the amount of information it can gather in terms of bits per second. It is evaluating the amount of information acquired versus some amount of time spent. And the amount of time considered is an important factor, because if you maximize this problem over too short an amount of time, you will arise at a suboptimal, “greedy” optimization. It’s harder to maximize it over a longer period of time given that there are more unknowns, but in general, this approach will lead to superior solutions.
Why is it better to evaluate an optimization problem over a longer time horizon?
When you plan your route to a destination, you don’t think about what the next three steps will be. Instead, you think about where you’re going, and the best trajectory to get from where you are to where you want to go. You’re thinking on a longer-term horizon, and trying to optimize with respect to that, rather than just taking three or four steps and then taking three or four more steps.
You’re able to do that because you have some sense of the way that the environment will unfold. based upon your historical experience. You’ve developed insights into how environments typically are structured based upon trends you have witnessed through prior observation. And that allows you to make decisions regarding where you should go, and to optimize your path in order to guide yourself there as quickly as possible. You can leverage that general sense to help you make decisions, even in the face of uncertainty, because you have learned something previously.


